After collecting a good amount of baby feeding data, I wanted to take the next step: build a predictive model. The idea was simple—could I predict either the amount of milk in the next bottle or the time until the next bottle? If the model worked well, it might offer a useful tool for planning daily routines.
Here’s the process I followed:
- Data preparation. I split the bottle data into the right format, carefully enforcing time and numerical fields so that the models had clean inputs.
- Feature engineering. I calculated moving averages, rolling windows, and extracted calendar-based features such as day of week and hour of day.
- Model experimentation. I tried several regression models to see which one could capture the patterns best.
- Data splitting. I divided the dataset into training, testing, and validation sets.
- Pipelines. I created a training pipeline that automatically fit all the models and returned the best performer.
- Evaluation. I built analysis plots and ran predictions to evaluate how well the models worked.
My strategy was to use two separate models:
- One model predicted the amount of milk in the next bottle (in milliliters).
- The other model predicted the time until the next bottle (in minutes).
Both were regression models, trained independently.
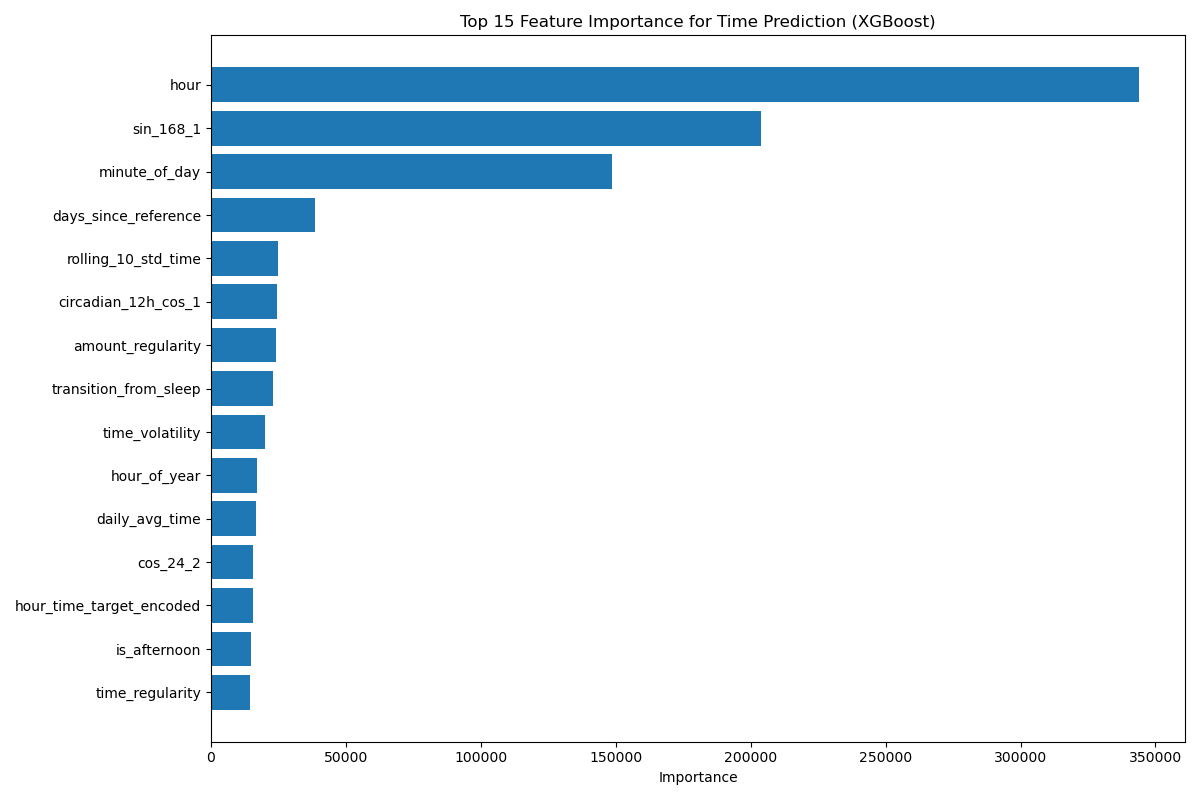
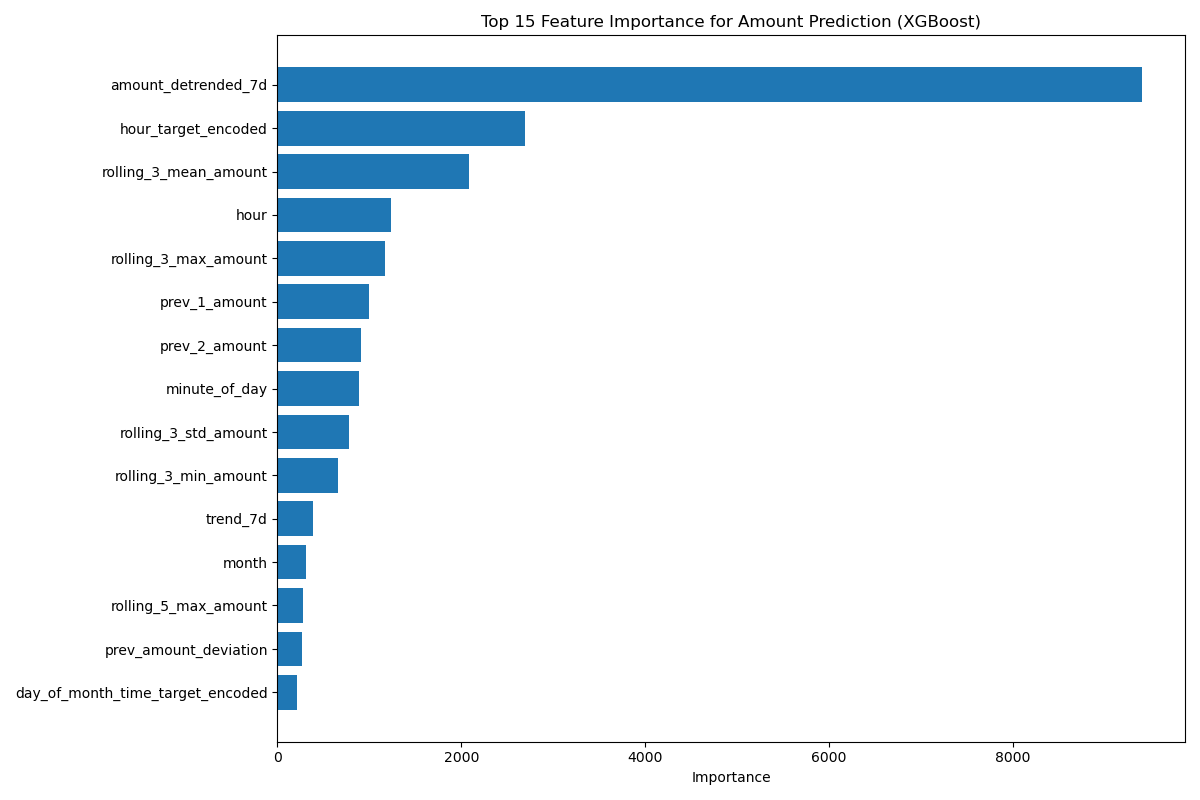
The results, however, were mixed. The fit wasn’t great. Predictions varied wildly—from nearly 0 to 12 hours between bottles. I experimented with ensemble models, cross-validation, and even a walk-forward validation strategy designed for time series data. While these helped improve stability a bit, the core problem remained.
The main challenge is that the two variables—amount and timing—are not independent. A baby who drinks a large bottle may wait longer for the next one, and vice versa. Modeling them separately breaks the relationship. On top of that, feeding data has a trend-like structure (gradual growth, then eventual decline), which makes single-event predictions harder. Moving differences and detrending helped somewhat, but at the cost of losing valuable data points.
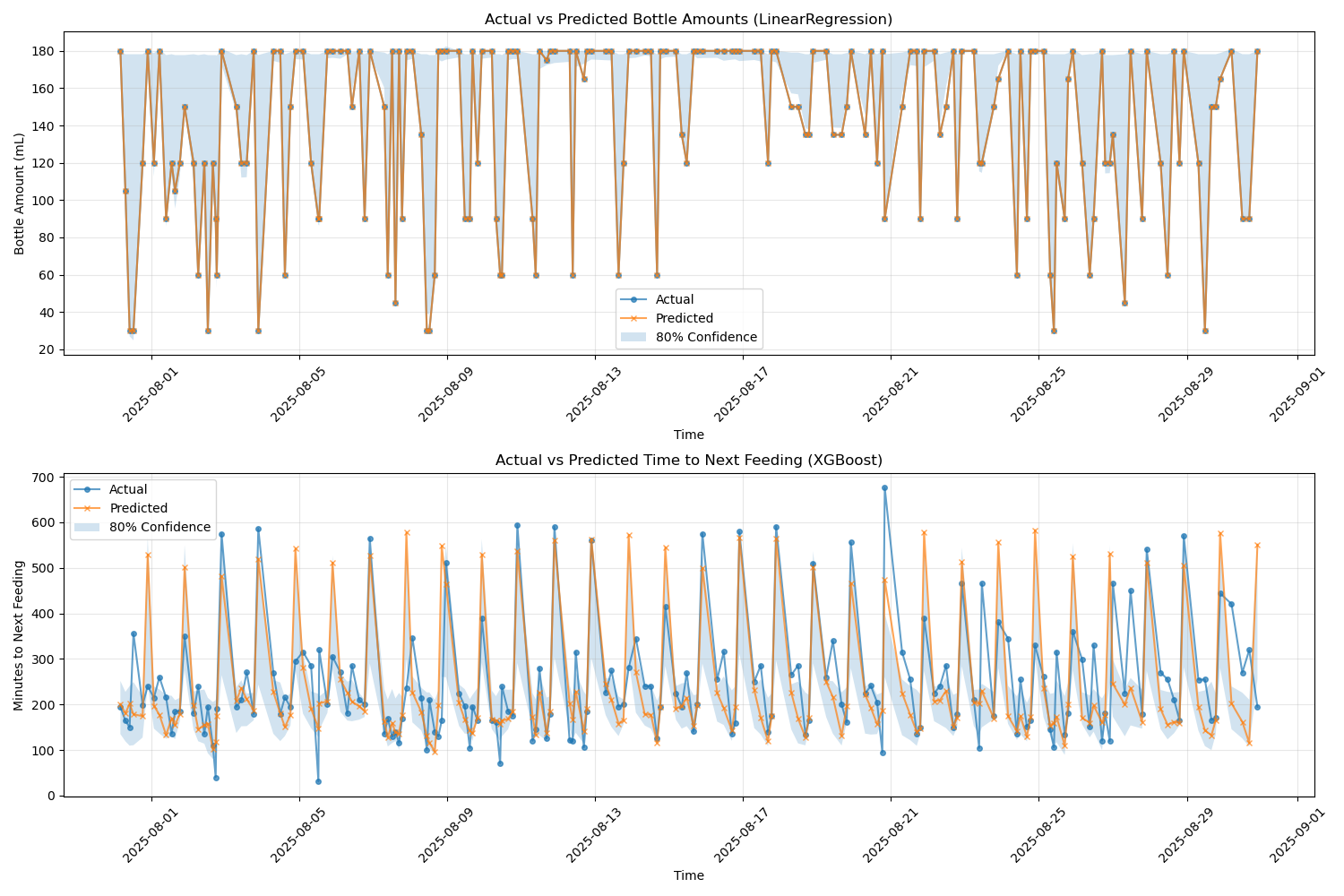

Ultimately, I hit a fundamental limitation: the dataset is too small. A few hundred points is rarely enough to train robust regression models, especially when the underlying process is complex and coupled.
The lesson here is that this problem is really a time series challenge. Bottles follow daily rhythms, short-term fluctuations, and long-term trends. Treating them as independent regression tasks misses that structure. Next, I’ll try vanilla time series methods.

Even though the first attempt wasn’t perfect, it was a valuable experiment. It clarified what makes feeding data hard to model and highlighted the importance of choosing the right tool for the problem.